|
Research /
Authorship attribution from word adjacency networksWhat's in Shakepeare's name? For more than a century several crank theories have been popular in some literary circles stating that he whom we call Shakespeare didn't write any of the plays for which he is famous. There are some who believe that Shakespeare's plays were written by Francis Bacon, while some others believe the plays were written by Christopher Marlowe, and yet another group who thinks that Edward de Vere, Earl of Oxford, is the author of the plays that we attribute to William Shakespeare of Stratford upon Avon. This latter theory has recently captivated popular imagination upon the release of the movie "Anonymous." Although these alternative Shakespearean authorship hypotheses have had prominent advocates throughout history reputable Shakespearean scholarship gives them little credence. Nevertheless, there are many open questions about the authorship of some Shakespearan plays going from the uncertain attribution of the "The Taming of the Shrew" to the almost certain fact that some plays where written in collaboration with contemporary authors.  Figure 1. List of authors used to test accuracy of classification with word adjacency networks. The total number of texts available for each author are also shown. There are, therefore, several important questions regarding Shakespearean plays: (i) Who wrote these plays. (ii) Were these plays written by a single person? (iii) If there are collaborators, who were they? To put it in Shakespearean language the question is: What's in Shakepeare's name? Shakespeare himself, whomever he, she, or they were, provided an answer to the most fundamental aspect of this question: What's in a name? That which we call a rose
by any other word would smell as sweet.
In the end, it doesn't matter if "The Tempest" was written by William Shakespeare, Francis Bacon, Christopher Marlowe, Edward de Vere, or a team of anonymous writers. It would still be a beautiful play and two of my children would still be called Miranda and Ariel. Yet, the third one may not had been named Guille (the Spanish language version of William). His name could had been Francisco (Francis), Cristobal (Christopher), or Eduardo (Edward) instead. This would be catastrophic in many accounts, but it could be worse. It is possible that he should have multiple names some of which may not be known at all. On a more important note, it is impossible to get a researcher to waste enough time on a question he believes he can answer. The purpose of this project is therefore to answer the question: What's in Shakespeare name? Or to put in less poetic terms our goal is to develop methods for authorship attribution. Besides its use in answering authorship questions about playwrights of the English Renaissance, the tools we are developing are applicable in data forensics as well as well as to the detection of plagiarism and other forms of academic malfeasance. 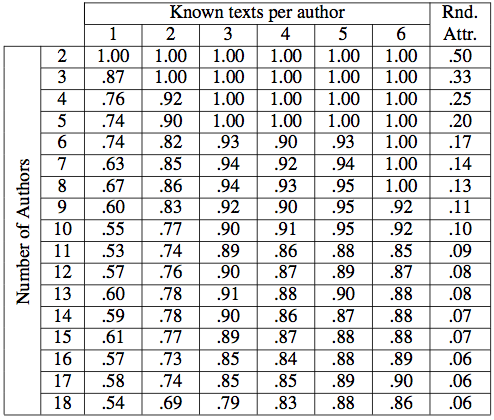 Figure 2. Accuracy for different number of candidate authors and number of known texts per author. Expected accuracy of random attribution is also informed. Accuracy decreases with increasing number of authors and decreasing number of training texts per author but remains large in most situations. The goal of authorship attribution is to match a text of unknown or disputed authorship to one of a group of potential candidates. More generally, it can be seen as the search for a compact representation of an author's writing style, or stylometric fingerprint. Applications of this study range from forensics to questions of plagiarism in the works of both published authors as well as students. With recent developments in computational efficiency and information processing, authorship attribution studies are of both increasing interest and accuracy. The study of authorship attribution, sometimes called stylometry, has its beginnings in works published over a century ago which proposed distinguishing authors by looking at word lengths and average sentence lengths. These two rudimentary ideas have improved since. A significant development came with the introduction of the influential idea of analyzing function words as a way to characterize authors' styles. Function words are words like prepositions, conjunctions, and pronouns which on their own carry little meaning but instead help define grammatical relationships between words. The study of function words is beneficial as they primarily inform about syntax rather than content. Since the introduction of function words as stylometric fingerprints many methods have been introduced to analyze the frequency of these words in texts written by different authors. Attention has also been given to analyzing features other than appearances of high-frequency words. Examples of these are the use of vocabulary richness, word stability -- the extent to which a word can be replaced by an equivalent --, or syntactical markers like part-of-speech taggers. Our approach to authorship attribution focus on function words but instead of using their frequency distribution as an author signature we propose the use of the relational structure of function words. In order to classify the authorship of a text we compute an asymmetric network of function word adjacencies capturing how likely it is to find a particular function word within the next few words conditional on the occurrence of another given word. The resulting matrices can be interpreted as transition probabilities of a Markov chain. The similarity of different texts is then estimated by the relative entropy of these transition probabilities. We have tested the proposed methodology in authorship attribution problems including texts from up to 18 different authors using training sets consisting of between 1 and 6 known texts per author -- see Fig. 2. Estimation accuracy in the order of at least 90\% is observed in most cases. We have further demonstrated that our classifier performs better that classifiers based in word frequencies. Perhaps more important, numerical experiments show that classifiers based on word frequencies encode different stylometric fingerprints than the classifiers proposed here and can then be combined for increased attribution correctness. Ongoing work, acknowledgments and referencesWe are currently performing a comparative study of word adjacency networks for English authors of the Renaissance. From this study it can be easily seen that Bacon as well as Marlowe have stylometric fingerprints very different from the stylometric fingerprint of Shakespeare. This is, however, still on a preliminary stage. The technical ideas to generate and compare word adjacency networks for different authors come from the prolific imagination of Santiago Segarra. The actual legwork of comparing networks and running numerical analyses has been undertaken by Mark Eisen. Mark is a rising senior at Penn. If you are looking for a promising fresh graduate to hire, Mark is sure to do an impressive job on whatever that is. Our preliminary results have appeared here:
The lists of texts we used in the performance evaluation discussed here are listed in Mark's webpage. In the same page you can download the corresponding word adjacency networks built from the given texts as well as the codes we used to generate the word adjacencies and compute distances between them. |