KernelRegression
Kernel Regression
Two of the shortcomings of the K-NN method is that all neighbors receive equal weight and the number of neighbors must be chosen globally. Kernel regression addresses these issues. Instead of selected nearest neighbors, all neighbors are used, but with different weights. Closer neighbors receive higher weight. The weighting function is called a kernel and it measures similarity (as opposed to distance) between examples. It is easy to convert from a distance {$d(\cdot, \cdot)$} to a kernel {$K(\cdot, \cdot)$}. One of the most common ways is the Gaussian-type kernel (ignoring the normalization):
{$K(\mathbf{x},\mathbf{x}_i) = \exp\{\frac{-d^2(\mathbf{x},\mathbf{x}_i)}{\sigma^2}\}$}
Kernel Regression/Classification Algorithm
- Given training data {$D=\{\mathbf{x}_i,y_i\}$}, Kernel function {$K(\cdot,\cdot)$} and input {$\mathbf{x}$}
- (regression) if {$y \in \mathbf{R}$}, return weighted average:
{$\hat{y}(\mathbf{x}) = \frac{\sum_{i=1}^{n} K(\mathbf{x}, \mathbf{x}_i) y_{i}}{\sum_{i=1}^{n} K(\mathbf{x}, \mathbf{x}_i)}$}
- (classification) if {$y \in \pm 1$}, return weighted majority:
{$\hat{y}(\mathbf{x}) = sign(\sum_{i=1}^{n} K(\mathbf{x}, \mathbf{x}_i) y_{i})$}
In kernel regression/classification, nearby points contribute much more to the prediction. A key parameter in defining the Gaussian kernel is {$\sigma$}, also called the width, which determines how quickly the influence of neighbors falls off with distance.
Below is a result of varying {$\sigma$}, from 0.5 to 8, which makes the prediction smoother, as more neighbors weigh in (note that due to a bug in Matlab, {$\sigma$} is displayed as the letter 'c'):
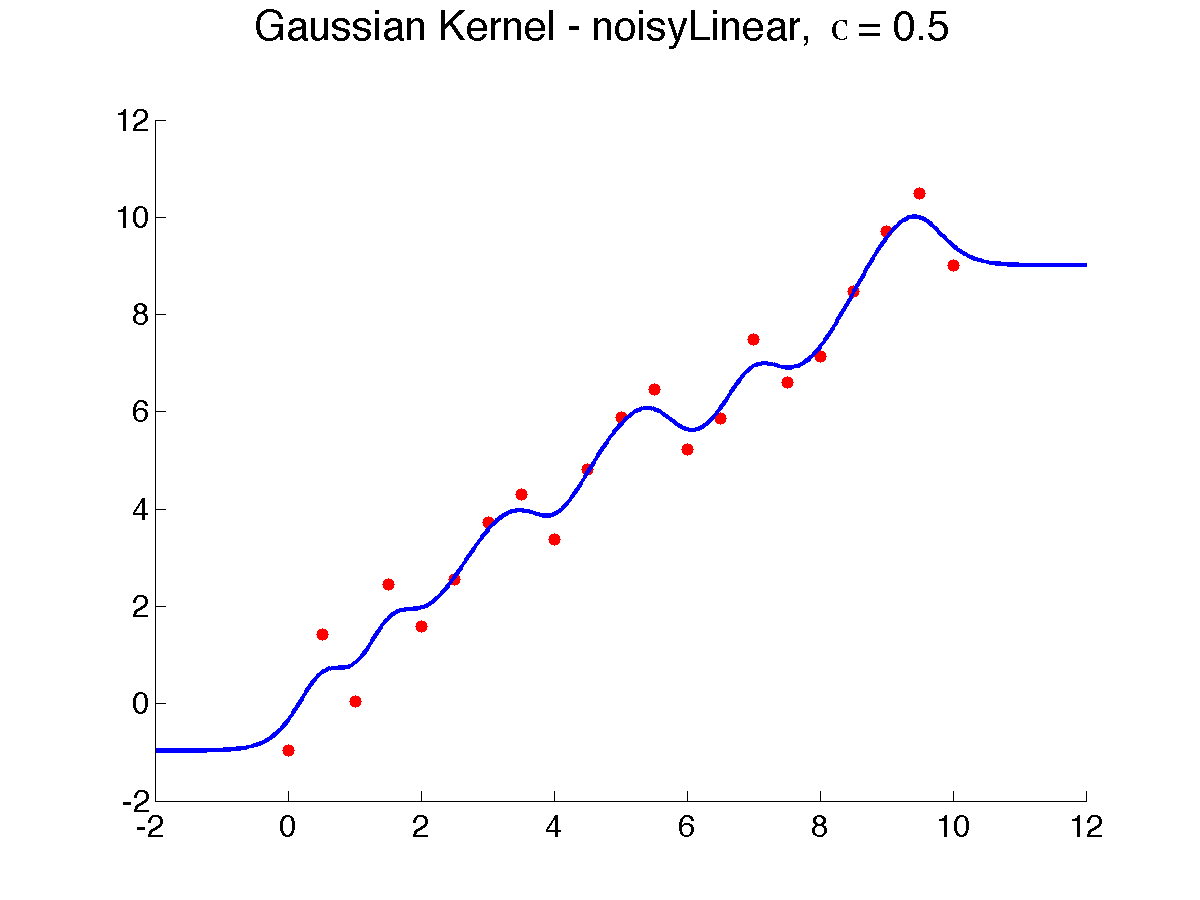
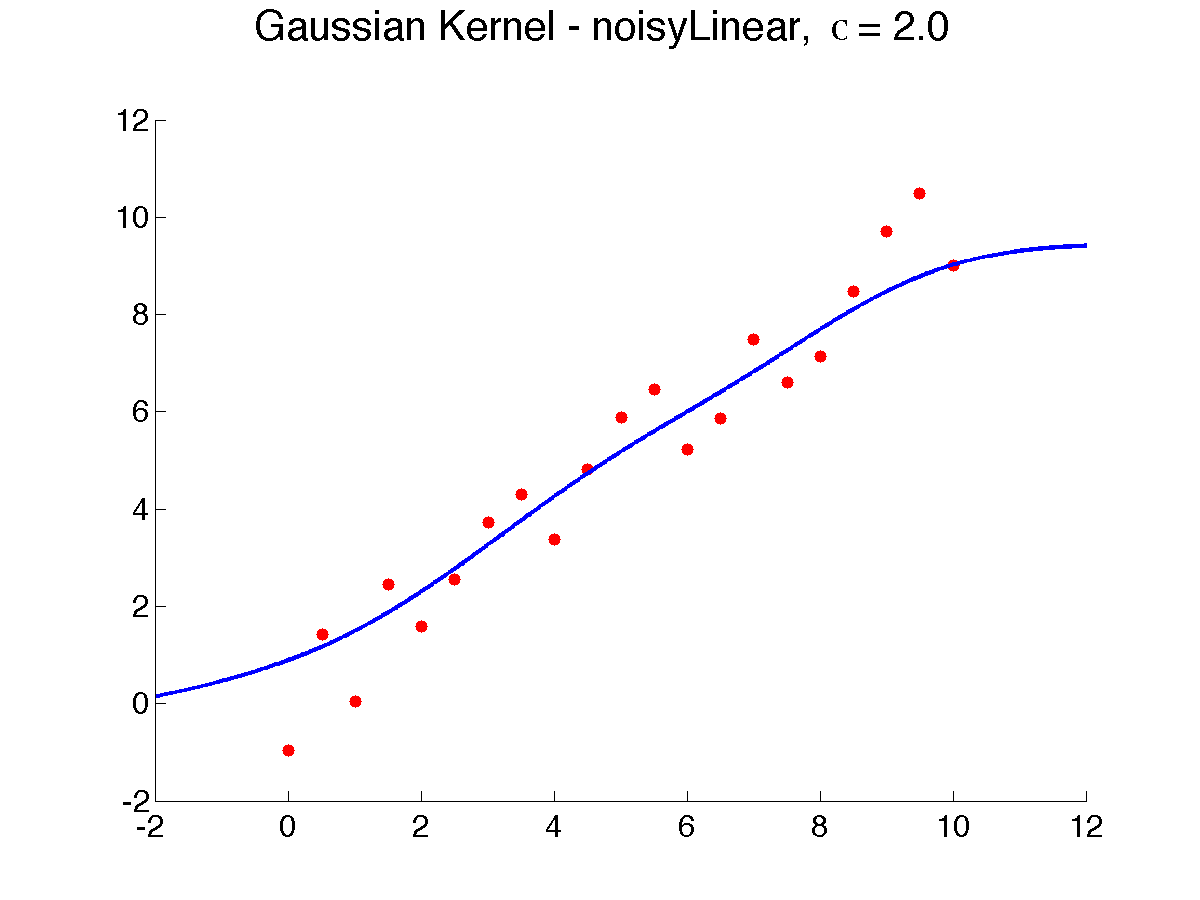
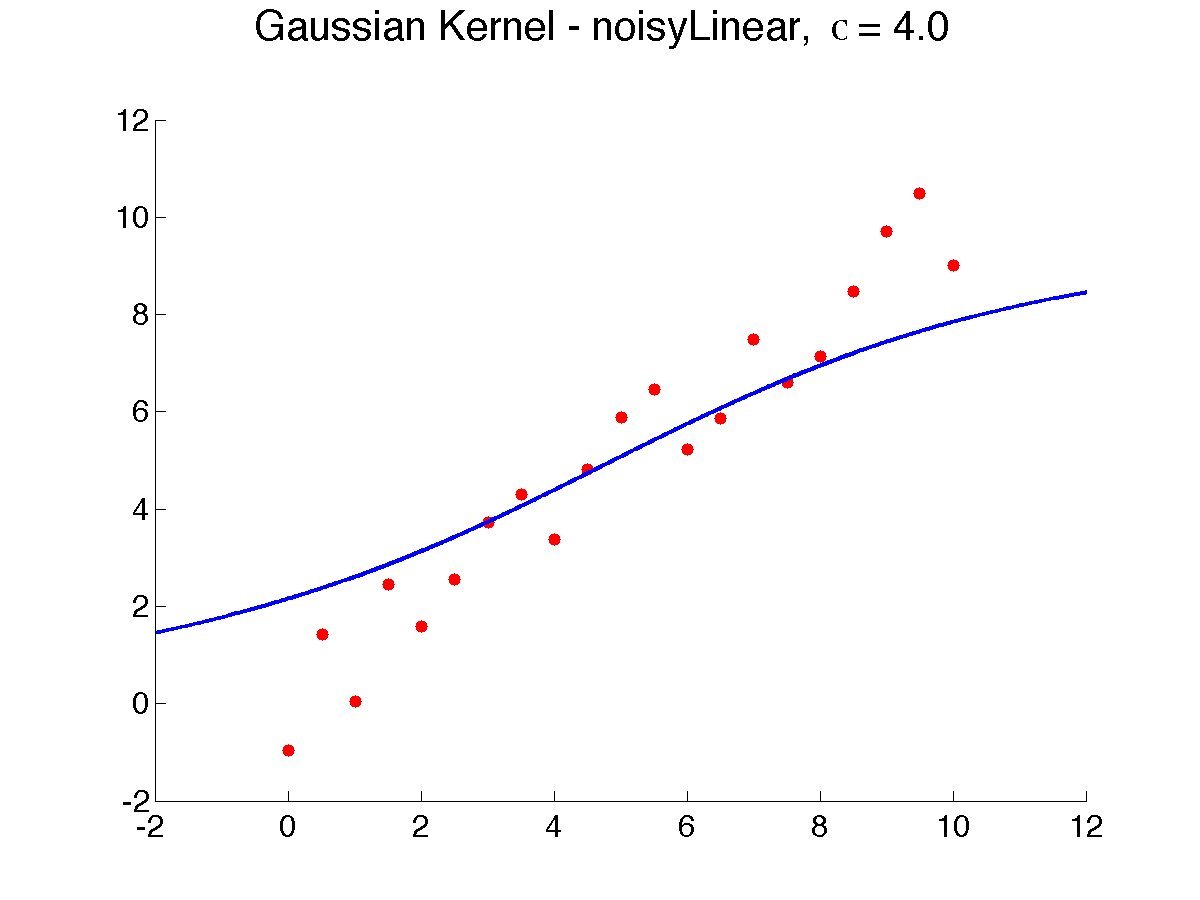
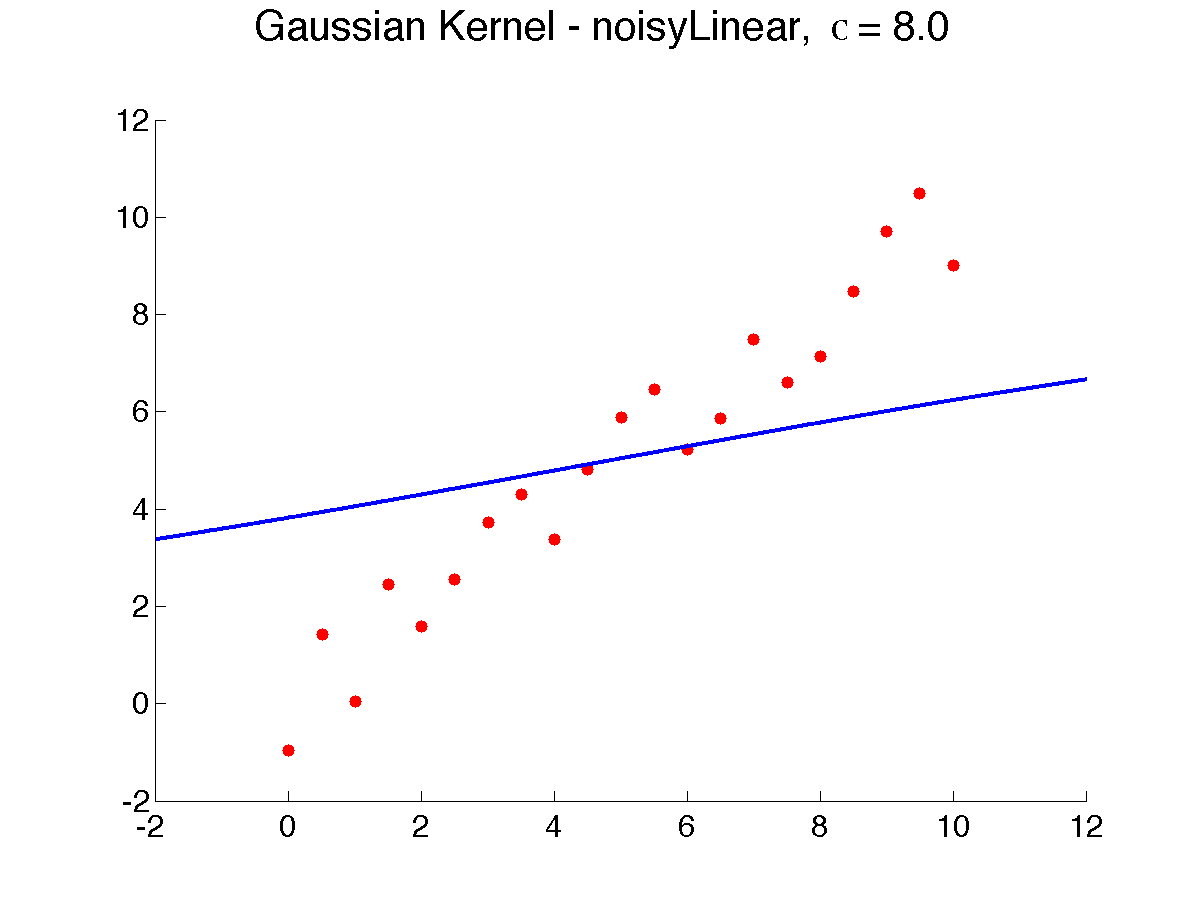
As {$\sigma \rightarrow \infty$}, all the neighbors weigh the same and the prediction is the global average or global majority and as {$\sigma \rightarrow 0$}, the prediction tends to 1-NN. Choosing the right width is extremely important to get the bias right. How? Cross-validation is often used .
Here's a result of using good kernel width on our examples ({$\sigma = 0.5$}):
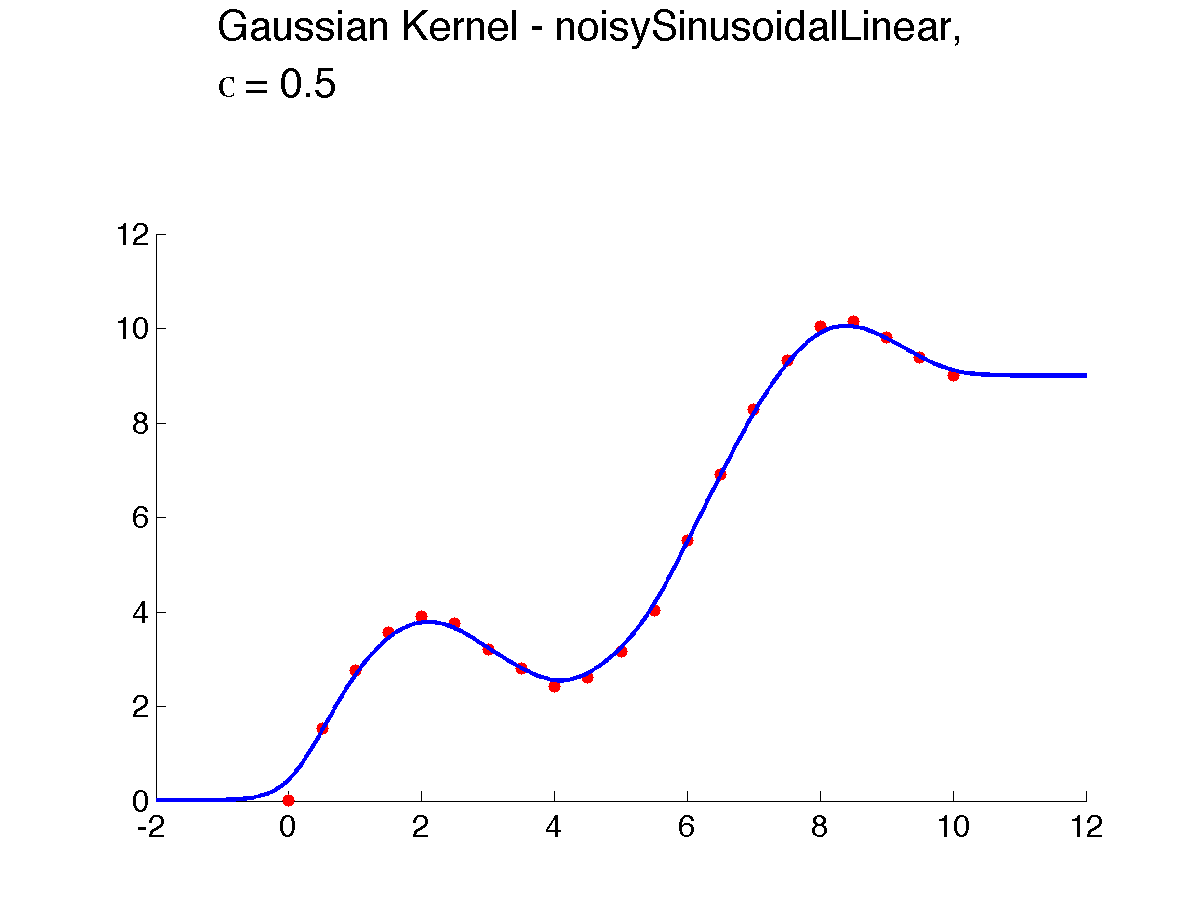
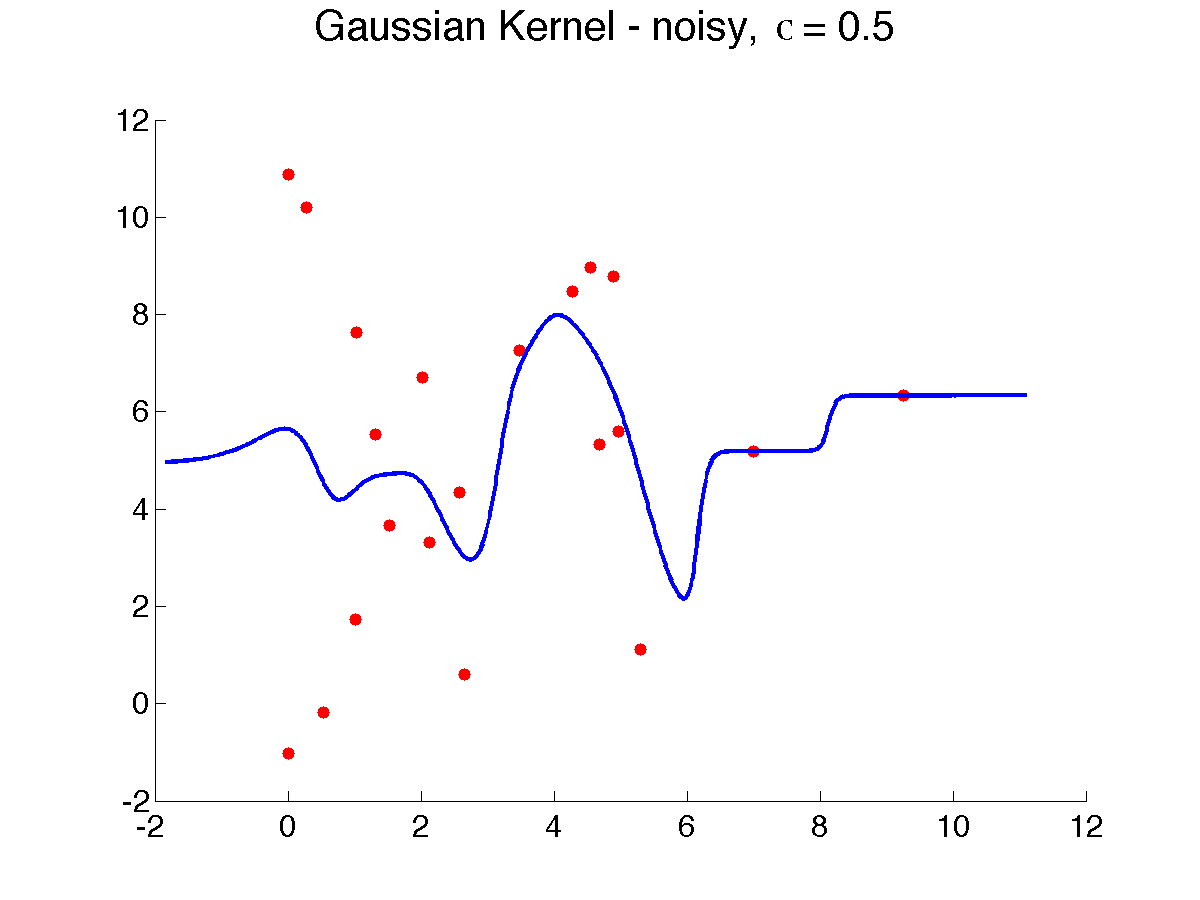
There results are quite good, but some artifacts remain at the boundaries.
Finally, let's apply kernel regression on the 2D toy dataset with kernel width of 2, and compare to increasing the neighborhood size:
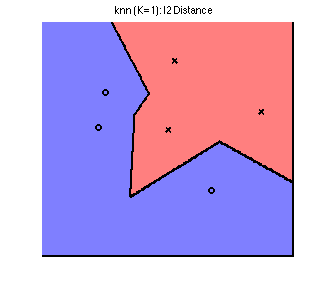
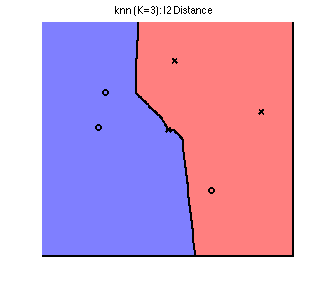
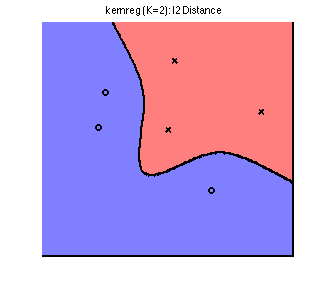
We see that we have achieved smoothness without misclassifying an additional training point.
Sample code
Scikit learn does kernel ridge regression
Summary of Local Learning Methods
| Algorithm | 1-NN | K-NN | Kernel Reg |
|---|---|---|---|
| Distance metric | any | any | not used |
| Number of neighbors | 1 | K | all |
| Weighting function | none | optional | positive kernel |
| Local model | none | (weighted) mean | weighted mean |