Bias VarianceOn this page… (hide) 1. Bias-Variance Decomposition in RegressionSuppose we want to fit the following regression prediction model: {$h: \mathbb{R} \mapsto \mathbb{R} = h(x) = c$}, which is constant for all {$x$}, to some data. Now, suppose the actual underlying model that generated the data is {$y = ax$}, where {$a$} is a constant slope. In other words, we are modeling the underlying linear relation with a constant model. We are going to compute the bias and variance of {$h$} under this scenario, or in other words, the bias and variance of trying to fit a line with a single constant. For this problem, we will consider all data to be noise-free. Consider a particular training set {$D$} where the inputs are {$ \{x_1, x_2\} $} and the responses are {$y_1 = a x_1, y_2 = a x_2$}, as shown in the figure below where {$y = g(x)$} and {$h = f(x)$} are fit using least squares. 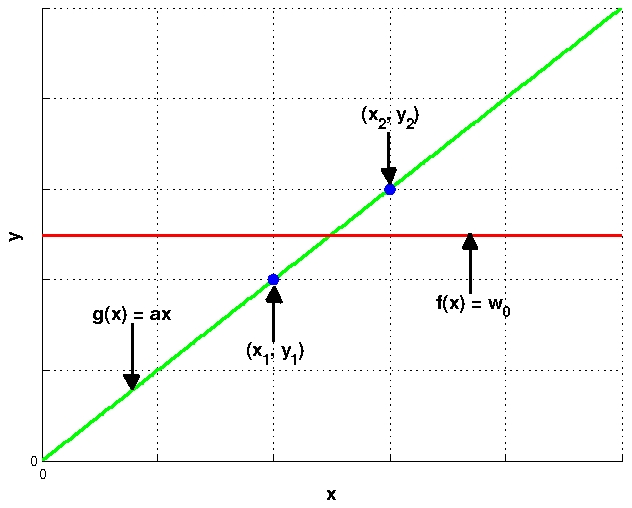 The curves {$\hat{f}_D(x)$} and {$g(x)$} Question: Compute the least squares estimate of {$h(x; D)$} given a dataset of {$n$} points {$D = \{x_1, \dots, x_n\}$} (Your answer should be in terms of {$a$} and {$x_i$}s.) {$c = \arg\min_{c'} \sum_{i=1}^n (c' - ax_i)^2 = \frac{1}{n}\sum_{i=1}^n (c'^2 - 2ac'x_i + a^2x_i^2)$} Taking the derivative with respect to {$c'$}: {$0 = \frac{1}{n}\left(2nc' - 2a\sum_{i=1}^n x_i\right)$} {$c = \frac{a}{n}\sum_{i=1}^n x_i $} So we see that we are simply taking the mean of the observed {$y$} values, {$ \; \{ax_1, \dots, ax_n\}$}. Question: Assuming standard least squares fitting, for what values of {$a$} will the bias of our model be 0? For what values of {$a$} will the variance be 0? Bias and variance are 0 for {$a = 0$}, since in that case the estimated model is the line {$y = 0$}, which is exactly the true model, regardless of the sampled data. Question: Let’s now try to compute the bias and variance of our method. Assume that {$x \sim \mathcal{N}(\mu, \sigma^2)$}. Compute the average hypothesis {$\bar{h}(x)$} over datasets {$D = \{x_1, \dots, x_n\}$}: {$ \begin{align*} \mathbb{E}_D [h(x;D)] & = \mathbb{E}_{x_1, \dots, x_n} \left[ \frac{a}{n}\sum_{i=1}^n x_i \right] \\ & = \frac{a}{n}\sum_{i=1}^n \mathbb{E}[x_i] \\ & = a\mu \end{align*} $} Question: Now compute the {$bias^2$} of the model: {$\mathbb{E}_x [ (\bar{h}(x) - \bar{y}(x))^2 ]$}. Remember that for this problem, {$\bar{y}(x) = y = ax$} since we are assuming there is no noise. {$ \begin{align*} \mathbb{E}_x [ (\bar{h}(x) - \bar{y}(x))^2 ] & = \mathbb{E}_x \left[ (a\mu - ax)^2 \right] \\ & = \mathbb{E}_x \left[ a^2\mu^2 - 2a^2x\mu + a^2x^2 \right] \\ & = a^2\mu^2 - 2a^2 \mu \mathbb{E}[x] + a^2\mathbb{E}[x^2] \\ & = a^2\sigma^2. \end{align*} $} So we see that the bias depends on the slope {$a$} and the variance {$\sigma^2$} of the underlying data model: the higher the slope, the worse our approximation is. However, as {$\sigma^2 \rightarrow 0$}, our approximation gets better, since the data gets closer and closer to a single point (regardless of slope). Question: Compute the variance: {$var = \mathbb{E}_x[\mathbb{E}_D[(h(x;D) - \bar{h}(x))^2]]$}. {$ \begin{align*} \mathbb{E}_x[\mathbb{E}_D[(h(x;D) - \bar{h}(x))^2]] & = \mathbb{E}_{x,D} \left[ \left(\frac{a}{n}\sum_{i=1}^n x_i - a\mu\right)^2 \right] \\ & = a^2 \mathbb{E}_{x,D}\left[ \left(\frac{1}{n}\sum_{i=1}^n(x_i - \mu) \right)^2\right] \\ & = a^2 \textrm{Var}\left(\frac{1}{n}\sum_{i=1}^n(x_i - \mu) \right) + a^2 \left(\mathbb{E}_{x,D}\left[\frac{1}{n}\sum_{i=1}^n(x_i - \mu) \right]\right)^2 \\ & = a^2 \frac{1}{n^2} \sum_{i=1}^n \textrm{Var}(x_i-\mu) \\ & = \frac{\sigma^2 a^2}{n} \end{align*} $} So we see that like the bias, our variance depends on {$a$} and the variance {$\sigma^2$}. However, this time we can improve variance by increasing the number of samples {$n$}. This is a general trend we will find for any method: increasing data reduces the variance of our method. |