|
Lectures /
HM MsOn this page… (hide) Hidden Markov ModelsHMMs are probably the most popular directed graphical model out there. They are used in many sequential and temporal domains: speech recognition, handwriting recognition, visual target tracking, machine translation, robot localization, gene prediction, and many more. In HMMs, the random variables are divided into hidden states (phonemes, letters, target location) and observations (audio signal, pen strokes, target image). The goal, as in supervised learning, is to predict the states from observations. For example, guess what this sound wave is saying? Speech recognition is getting better, but there is still a lot to learn. (Try holding a conversation with your phone.) 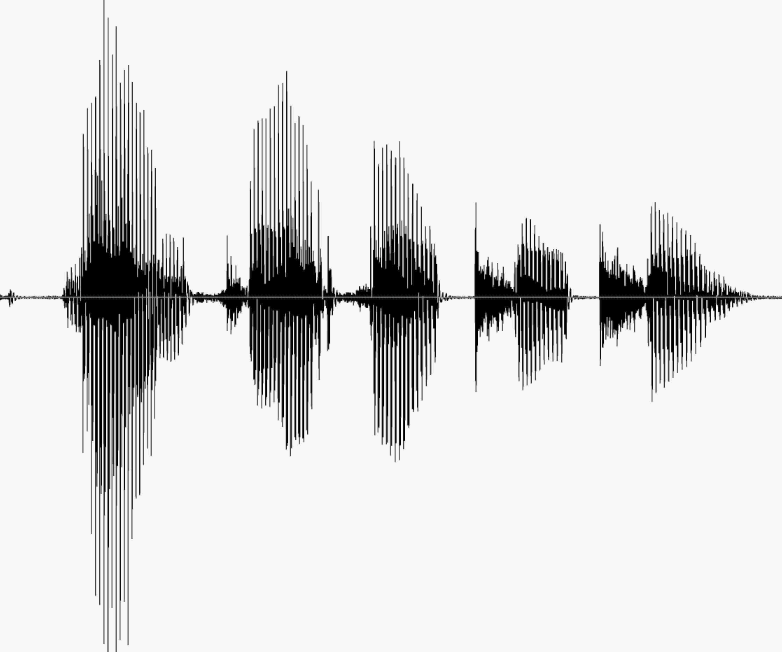
HMMs use the entire sequence of observation to predict the entire sequence of states. While individual observation may be ambiguous: 
In the context of the entire sequence, the ambiguity is often diminished. 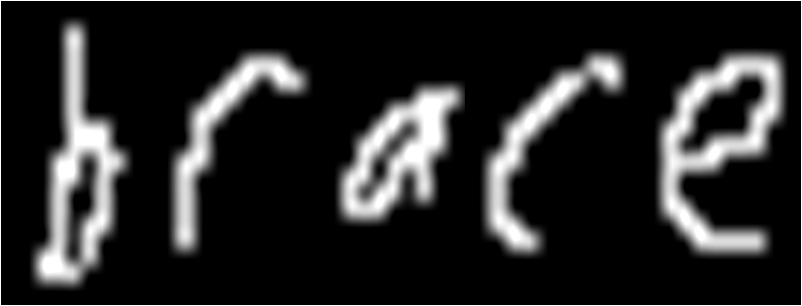
Let’s start with the simplest HMM, a 2-state, 2-observation model of the world: 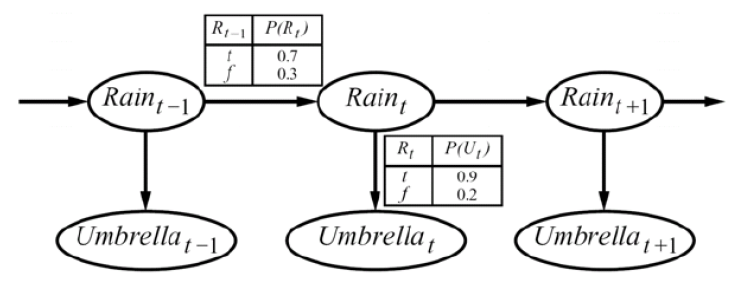
To define this HMM, we need:
More generally, we will denote the hidden states as {$X_i$} and observations as {$O_i$}. Hidden Markov Models with continuous hidden state and continuous observations are called Kalman Filters. We focus on the discrete states here. 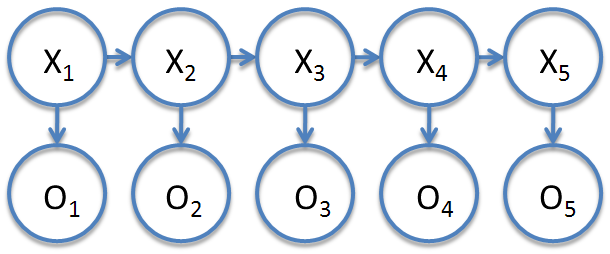
We will use the .. notation to denote a sequence and T to denote the length of the sequence and K the number of values that each state {$X_i$} can take.
With this notation, the HMM represents the joint probability over states and observations: {$ \begin{array}{l} P(X_{1..T} = x_{1..T},O_{1..T} = o_{1..T}) = \\ \quad\quad\prod_{i=1}^T P(X_i=x_i \mid X_{i-1} = x_{i-1}) P(O_i=o_i \mid X_i=x_i) \end{array} $} where {$P(X_1=x_1 \mid X_{0}=x_0) = P(X_1=x_1)$} for convenience of notation. Conditional Independencies in HMMs
HMM Inference - not covered this year. |